Knowledge Base Embedding using Retrieval Augmented Generation (RAG)
Why Knowledge Base Embedding
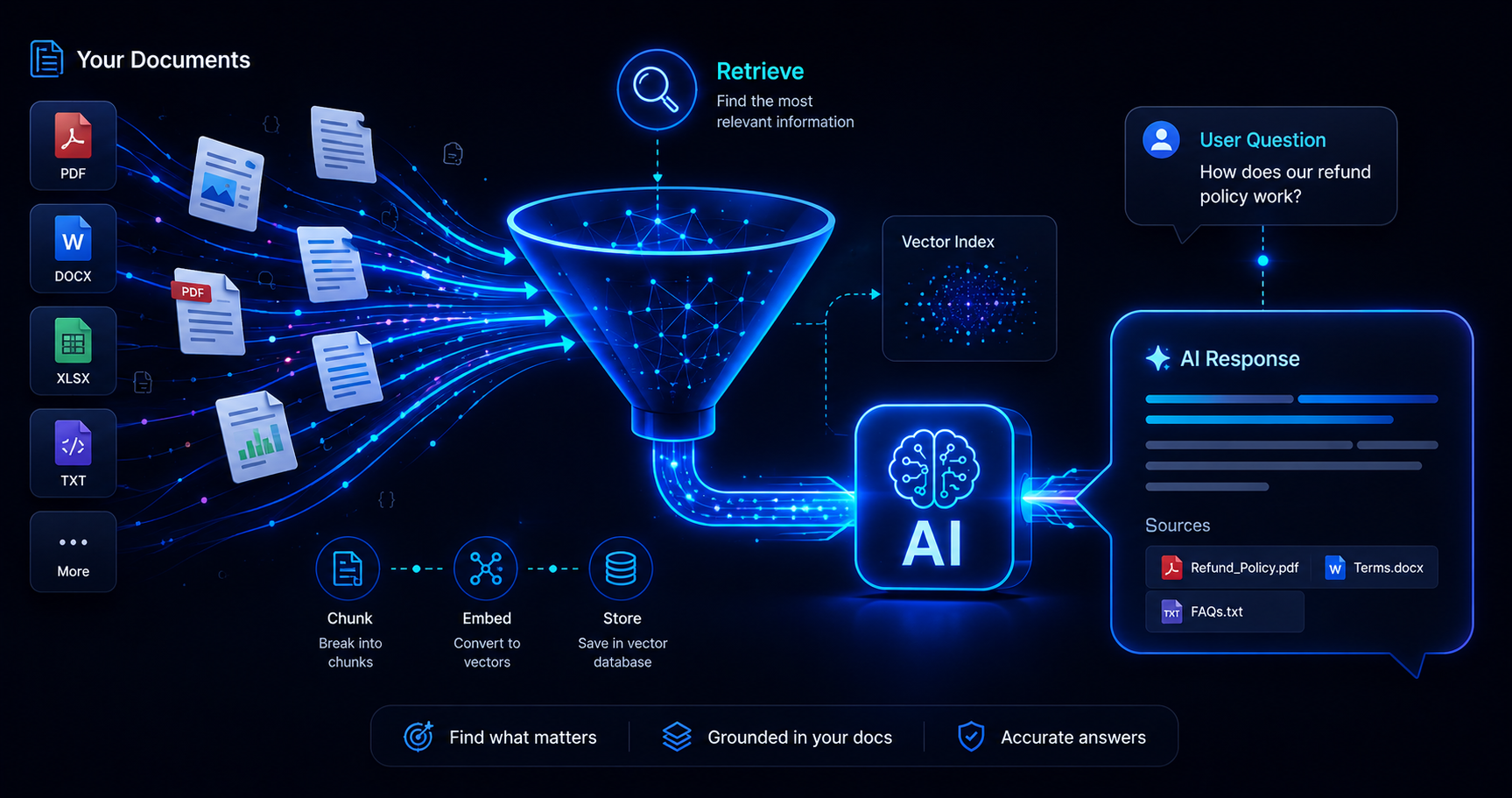
Suppose you have a very capable and powerful LLM, however, to use it you want it to have access to some domain knowledge. Say, you are working with some confidential data in your company and/or the knowledge base for your LLM keeps on changing. This is where knowledge base embedding comes into the picture.
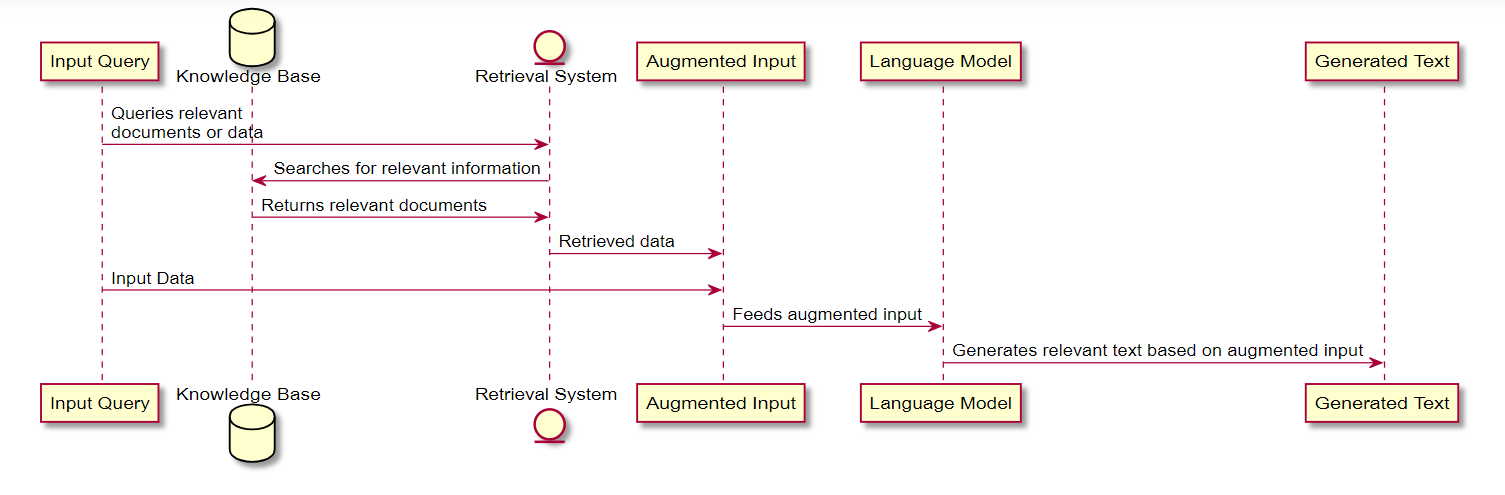
In knowledge base embedding, when the user asks a question, we search for the relevant information in the knowledge base and augment it to the user’s query. Hence the famous name “Retrieval Augmented Generation (RAG)”. The below diagram explains how RAG is done
Not sure whether RAG or fine-tuning is right for your use case? See Tailoring Language Models for Specific Tasks for a side-by-side comparison, or learn the alternative approach in Fine-Tuning LLMs for Behavioral Changes.
How to do RAG?
As mentioned above, RAG has two steps, search relevant information and augmenting it with the input for accurate results.
Searching for relevant information
To efficiently retrieve the relevant information based on the query, we generally use embedding and vector databases. Let’s quickly touch up on these…
Embedding and Vector Databases
Embedding: Embedding is nothing but a type of vector, that is representation of any data in the form of an n-dimensional vector. A good embedding is the one which groups similar data in the n-dimensional vector space and separates dissimilar data.
Embedding Models: Embedding models are those which are typically trained on very large datasets (can be of any kind like images, text etc…) where the data is converted into n-dimensional vectors.
Now, we have a way to represent any data in the form of a vector.
Vector Databases: Vector databases are the databases that are optimized for storing and retrieving vector data.
As mentioned earlier, embeddings are created in a way that similar data is grouped together in the n-dimensional vector space. This is often leveraged for quickly performing operations like similarity search on the vector database.
Retrieving Relevant information
Okay, now that we understood what embeddings are, let’s see how these embedding models are used to quickly retrieve relevant information for a user query in a simple way.
First, the user query is passed onto the embedding model creating a vector. This vector is used to find the closest vectors in the database which are considered as relevant vectors for the given query.
Implementing a RAG model
To do this, we need knowledge base (obviously) which we will preprocess to convert to vectors. Then we need an algorithm to perform similarity search, then we will combine the output with the LLM prompt.
Here’s how we can do this using langchain in python taking the following use case.
Example Use Case
Suppose you are managing customer support for multiple products and you have the historical data of all the closed tickets and their details. Whenever a new support ticket comes, you can use a RAG based system to find similar tickets and one step further, drive probable resolutions or identify patterns.
Dataset
To demonstrate this, I am using the kaggle dataset: Customer Support Ticket Dataset.
I have considered only the closed tickets from the database
This dataset has multiple fields in it but for the demonstration, I am interesting the “Ticket Description” and “Product Purchased” which will be taken as input from the user and guess the “Ticket Type” and “Ticket Subject” based on the inputs as well as similar historic data.
The dataset also contains a column for “Resolution” of the closed ticket which we could use to make the system provide potential resolutions for the ticket. However, at the time of writing this article, the data in the “Resolution” column is gibberish and not usable but if that data is also available, the same use case can be further extended.
Now that we have the required pre-requisites for the problem statement, we can proceed with the code in Python.
Install Required Packages
1
2
3
pip install langchain
pip install faiss-cpu
(optional) pip install faiss-gpu
FAISS is “Facebook AI Similarity Search” developed to perform efficient similarity search on vector databases. It is open source library and more details can be found here
Import required packages
1
2
3
4
5
6
7
8
9
10
11
12
from langchain_community.document_loaders import CSVLoader
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain_core.prompts.chat import (
ChatPromptTemplate
)
from langchain_core.messages import HumanMessage, SystemMessage
import os
In the further sections you will understand each of these imports and their uses.
Set up Open AI API Key
If you don’t already have an API key, please refer to this doc to set it up: Developer quickstart
1
os.environ['OPENAI_API_KEY'] = '<OPENAI_API_KEY_HERE>'
Load the data and split it into chunks
1
2
3
4
5
6
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = CSVLoader('Customer_Support_Tickets_Closed.csv', encoding="utf8").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Splitting the documents into chunks before vectorizing them is necessary because the LLM models have a maximum token limit. By splitting the documents into smaller chunks, you ensure that each chunk fits within the token limit and can be processed by the model. This allows RAG to effectively retrieve relevant information from the vector store during generation.
As mentioned in the Install Required Packages, FAISS is being used to convert the splitted data into a vector store/db. Also observe that OpenAIEmbeddings() is the embedding model that is used to convert the text into vectors and this uses the OPENAI_API_KEY environment variable set earlier.
Saving and Loading the Vector Database Locally
You may want to vectorize the data once and use it everytime you query the LLM for which you can use the below code to save the vector db locally and subsequently load it.
1
2
3
4
5
6
7
# Save the vector store to disk
db.save_local('faiss_db')
### The above code till here is generally a one time execution or periodic async execution if the data to be vectorized gets updated.
# Load the vector store from disk
db = FAISS.load_local('faiss_db', OpenAIEmbeddings(), allow_dangerous_deserialization = True)
The de-serialization relies loading a pickle file. Pickle files can be modified to deliver a malicious payload that results in execution of arbitrary code on your machine.You will need to set
allow_dangerous_deserializationtoTrueto enable deserialization. If you do this, make sure that you trust the source of the data. For example, if you are loading a file that you created, and no that no one else has modified the file, then this is safe to do. Do not set this toTrueif you are loading a file from an untrusted source.
Perform Similarity Search On The New Ticket
Let’s simply simulate the ticket by taking the product purchased and the user complaint as input.
1
2
3
4
5
6
7
product_purchased = input("Enter the product purchased: ")
query = input("Enter your query: ")
k = 3
similar_results = db.similarity_search(f'Product Purchased: {product_purchased}\nTicket Description: {query}', k=k)
contents = [doc.page_content for doc in similar_results]
Here k=3 denotes that 3 most similar data is retrieved by the similarity_search method.
For instance, below is the input that I have given
1
2
Enter the product purchased: Dell XPS 13
Enter your query: My device stopped turning on from yesterday. The charging indicator doesn't glow even after plugging in using the original charger.
And the 3 most similar rows returned for this are (Showing only the required columns)
| Product Purchased | Ticket Type | Ticket Subject | Ticket Description |
|---|---|---|---|
| Dell XPS | Technical issue | Network problem | I’m facing a problem with my {product_purchased}. The {product_purchased} is not turning on. It was working fine until yesterday but now it doesn’t respond. I really I’m using the original charger that came with my {product_purchased} |
| MacBook Pro | Billing inquiry | Account access | I’m facing a problem with my {product_purchased}. The {product_purchased} is not turning on. It was working fine until yesterday but now it doesn’t respond. No update of the product. The I’m using the original charger that came with my {product_purchased} but it’s not charging properly. |
| Dell XPS | Billing inquiry | Product compatibility | I’m facing a problem with my {product_purchased}. The {product_purchased} is not turning on. It was working fine until yesterday but now it doesn’t respond. If I’d just switched to a The issue I’m facing is intermittent. Sometimes it works fine but other times it acts up unexpectedly. |
Observe that the returned data is pretty similar to the new ticket.
Augment The Data To The Prompt
Once the similar data is retrieved, we can create a prompt that combines all the data obtained so far as below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
model = ChatOpenAI(model_name="gpt-3.5-turbo")
template_messages = [
SystemMessage(
content = f"""You are an assistant for helping to find solutions to customer support ticket by doing the following
1/ Guess the Ticket Type
2/ Guess the Ticket Subject
You need to guess these values based on the similar tickets that were resolved in the past. You will be provided with the last {k} similar tickets that were resolved."""
),
HumanMessage(
content = f"""Below is the information that the customer provided in the ticket.
Product Purchased: {product_purchased}
Ticket Description: {query}
Here is the last {k} similar tickets that were resolved:
{contents}
Please write the probable ticket type, ticket subject"""
)]
prompt = ChatPromptTemplate.from_messages(template_messages)
llm_chain = LLMChain(prompt=prompt, llm=model)
print(llm_chain.run({}))
The output for the earlier input with this prompt is
1
2
3
Probable Ticket Type: Technical issue
Probable Ticket Subject: Device not turning on
That’s all. Now you can apply the RAG technique to any data that you have.
For Non Csv data, langchain supports different data loaders. Please refer to this for more info: Document Loaders.